

LLM API Call or Agent? How Modern AI Gets (and Loses) Its Autonomy
An Engineer’s Guide to Choosing the Right Approach for Your LLM


Hey engineers and founders, let’s cut through the AI hype. Large Language Models (LLMs) can indeed do amazing things, from drafting emails to managing complex workflows—but there's a critical choice you’ll face when building your product: should you stick to direct API calls, orchestrate workflows through code, or dive into building autonomous agents?
This edition breaks down these choices with practical insights so you can confidently pick the right architecture and keep shipping fast.
TL;DR
Direct LLM calls: Perfect for predictable tasks.
Orchestrated workflows: Great for multi-step processes you control.
Autonomous agents: Ideal for open-ended, dynamic problem-solving.
But watch out—mixing these without clear boundaries can quickly lead to messy code, inflated costs, and brittle user experiences.
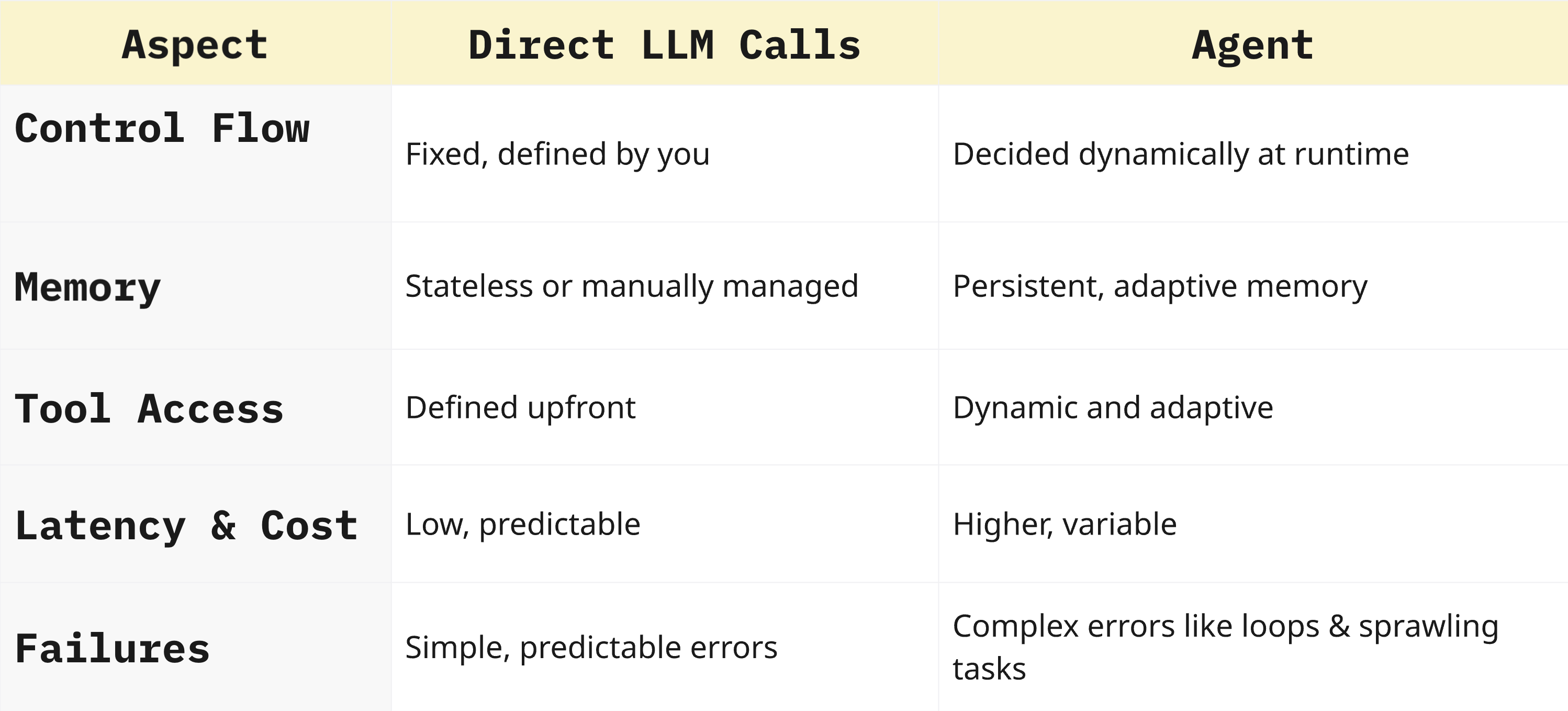
1. Mental models: choosing your path
Think of mental models as architectural blueprints for your brain—compact, reusable sketches that tame complexity and keep you shipping.
Whenever the project feels fuzzy, reach for a smaller mental model—not a heavier framework.
In the context of LLMs, these models guide you to pick the right layer of autonomy—direct call, orchestrated workflow, or full agent—without over‑engineering.
Here’s a quick guide to understand the landscape:
2. Understand the evolution: Single Calls → Code-Driven Workflows → Autonomous Agents
Every engineering team climbs the same autonomy ladder:
One‑shot LLM calls – a single prompt in, single answer out. Great for fast wins like summarization or sentiment tags.
Code‑orchestrated workflows – you chain several calls together with plain code. Each step tackles a bite‑sized, deterministic task; your glue code owns the flow.

Autonomous agents – when the happy path splinters into too many branches, you hand the steering wheel to the model. It plans, chooses tools, and loops until done.

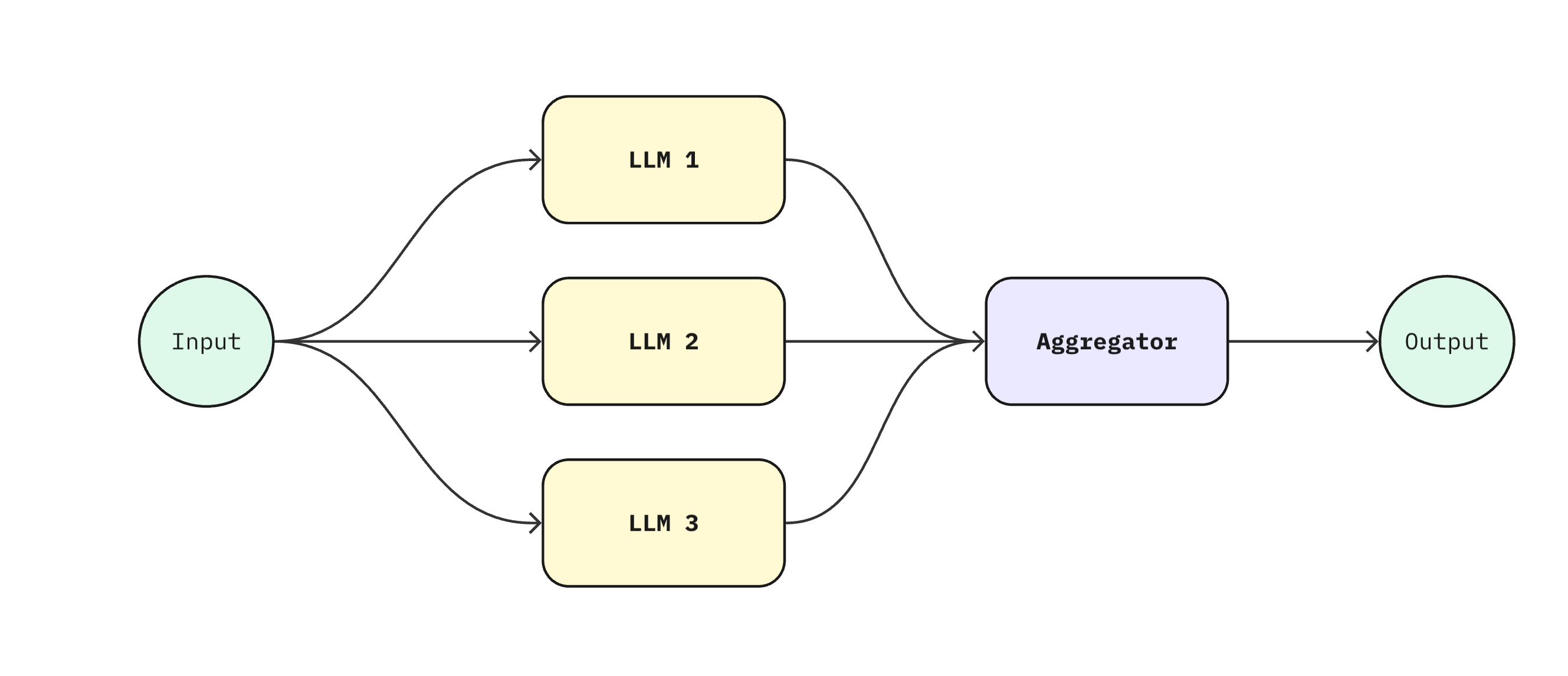
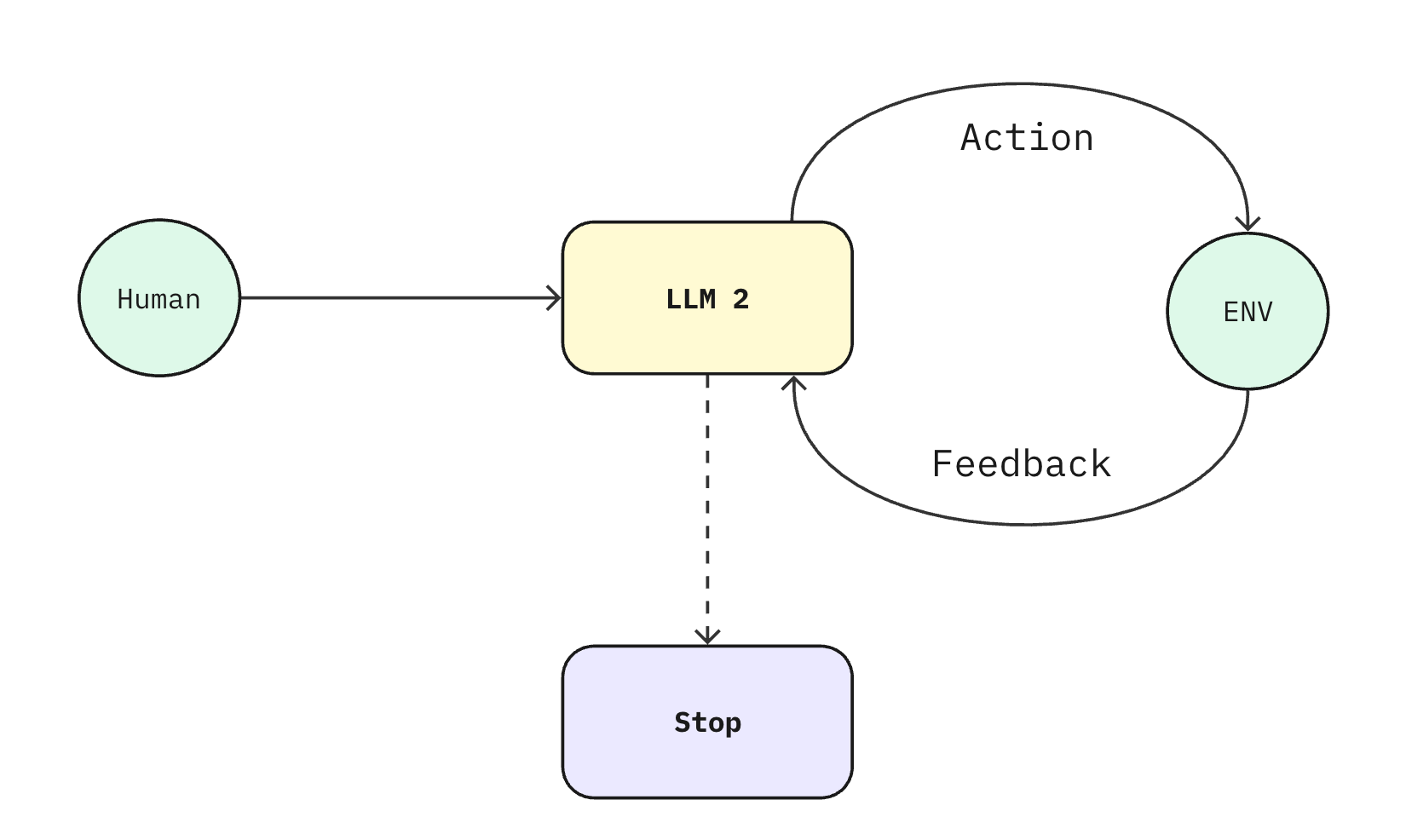
Think of it like transport:
Kick‑scooter (one‑shot): dead simple, zero maintenance.
Manual car (workflow): more parts, but you still drive.
Self‑driving car (agent): magical when it works, expensive when it doesn’t.
Choose the scooter when traffic is light, the car for regular commutes, and the self‑driving option only when the journey is too complex to steer manually.
Barry Zhang from Anthropic captures this evolution concisely:
Single LLM calls for quick, deterministic tasks.
Code-driven workflows for predictable complexity.
Autonomous agents when flexibility and dynamic decision-making are critical.
3. So, when does direct calls win
One‑and‑done language jobs: "Summarize this doc," "translate to Spanish," "tag the sentiment." One prompt in, answer out, ship it.
Straight‑through data plumbing: You already know the SQL or API shape—let the model populate parameters, nothing more.
Hard latency ceilings: Sub‑second chat replies, metered mobile apps, edge devices—no time for multi‑turn deliberation.
Audit‑friendly outputs: Legal templates, medical disclaimers, or anything compliance must rubber‑stamp. Fewer moving parts = fewer surprises.
4. When to let the Agent off the leash
Messy, branching quests: You don’t know the full roadmap upfront—think “Plan a month‑long Europe trip under $3k, factoring rail passes and food allergies.”
Live tool roulette: The job could hit ten different APIs, pick databases on the fly, and recover gracefully when half of them time out.
Self‑correct & iterate: Tasks where the model must read, evaluate, retry, and patch its own output—data cleanup, codebase migrations, literature reviews.
Always‑on guardians: Continuous monitoring, alert triage, or scheduled optimizations where memory and autonomy compound over time.
🎛️ Rule of thumb: If a human PM would need a whiteboard and sticky notes to map the path, an autonomous agent is probably the right sidekick.
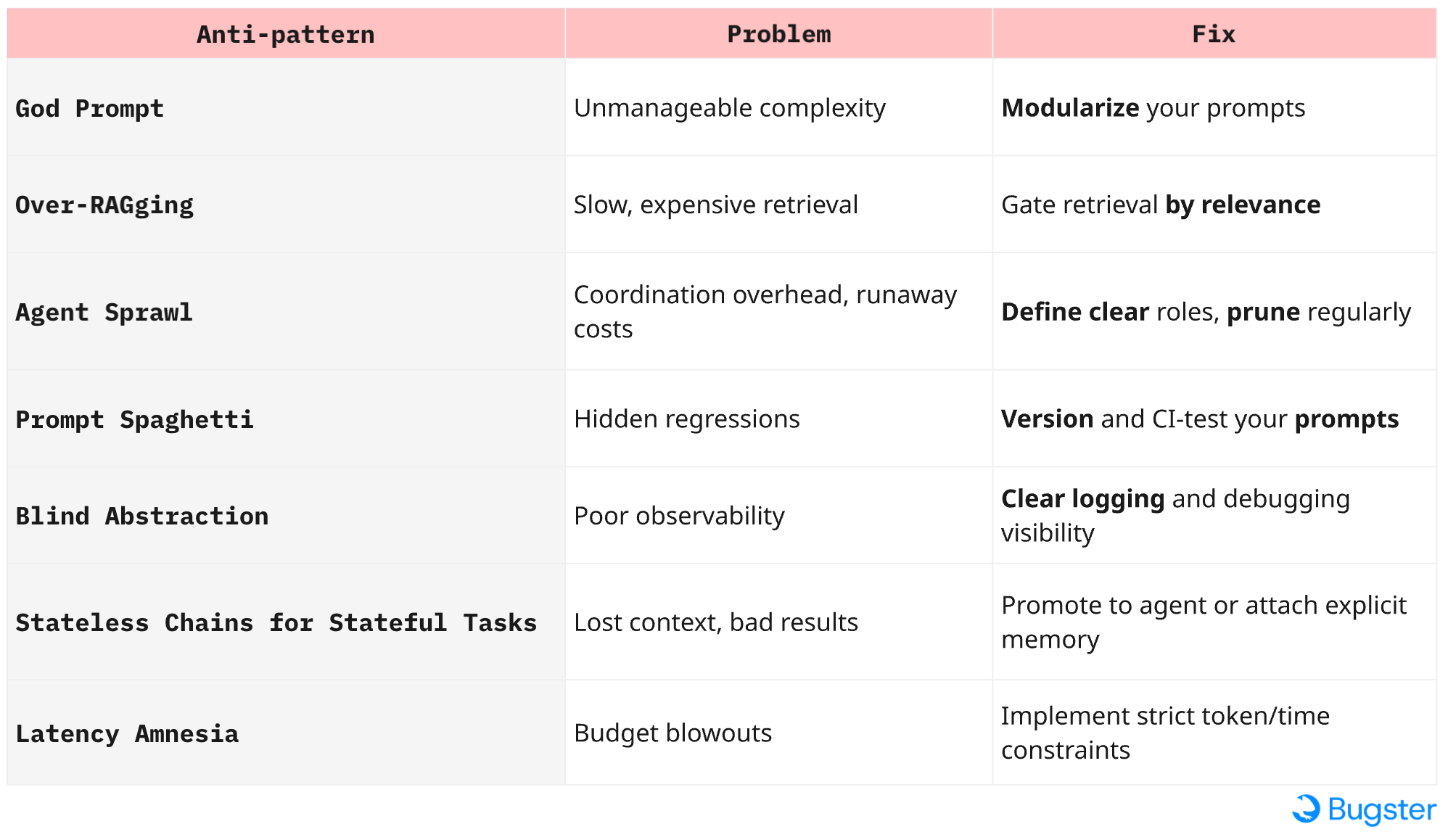
5. Anti-patterns to avoid
Before you reach for the shiny new framework, memorize this wall of shame. These patterns look tempting in the sprint rush, but every one of them shows up later as flaky tests, surprise bills, or 🔥🚒 2 a.m. PagerDuty pings.
6. Your LLM design checklist
Use this pre‑flight list before every deploy. Skip a box at your own peril.
Define the job in a sentence: If you can’t TL;DR the task, you’re not ready to prompt.
Choose the lightest model/tool that works: Smaller ≠ worse. Try the budget option first.
Map external actions: ≤ 3 well‑known APIs → direct call. > 3 or dynamic tool choice → consider an agent.
Set hard limits: Max tokens, turns, tool invocations, wall time. Automation without guardrails is just auto‑chaos.
Make thinking visible: Log raw prompts, intermediate scratchpads, and final outputs for post‑mortems.
Iterate outside‑in: Start with a working stub, then add autonomy only when the deterministic path buckles.
Design for observability: Dashboards, traces, and real‑time alerts—so issues surface before users tweet them.
Print it, stick it next to your monitor, and run it like a pre‑flight checklist every time you touch production.
Don’t let hype choose for you. Test often, iterate carefully, and maintain clarity in your system’s logic. Your future self—and your budget—will thank you.
Happy building! 🚀
 | A guest post by
|